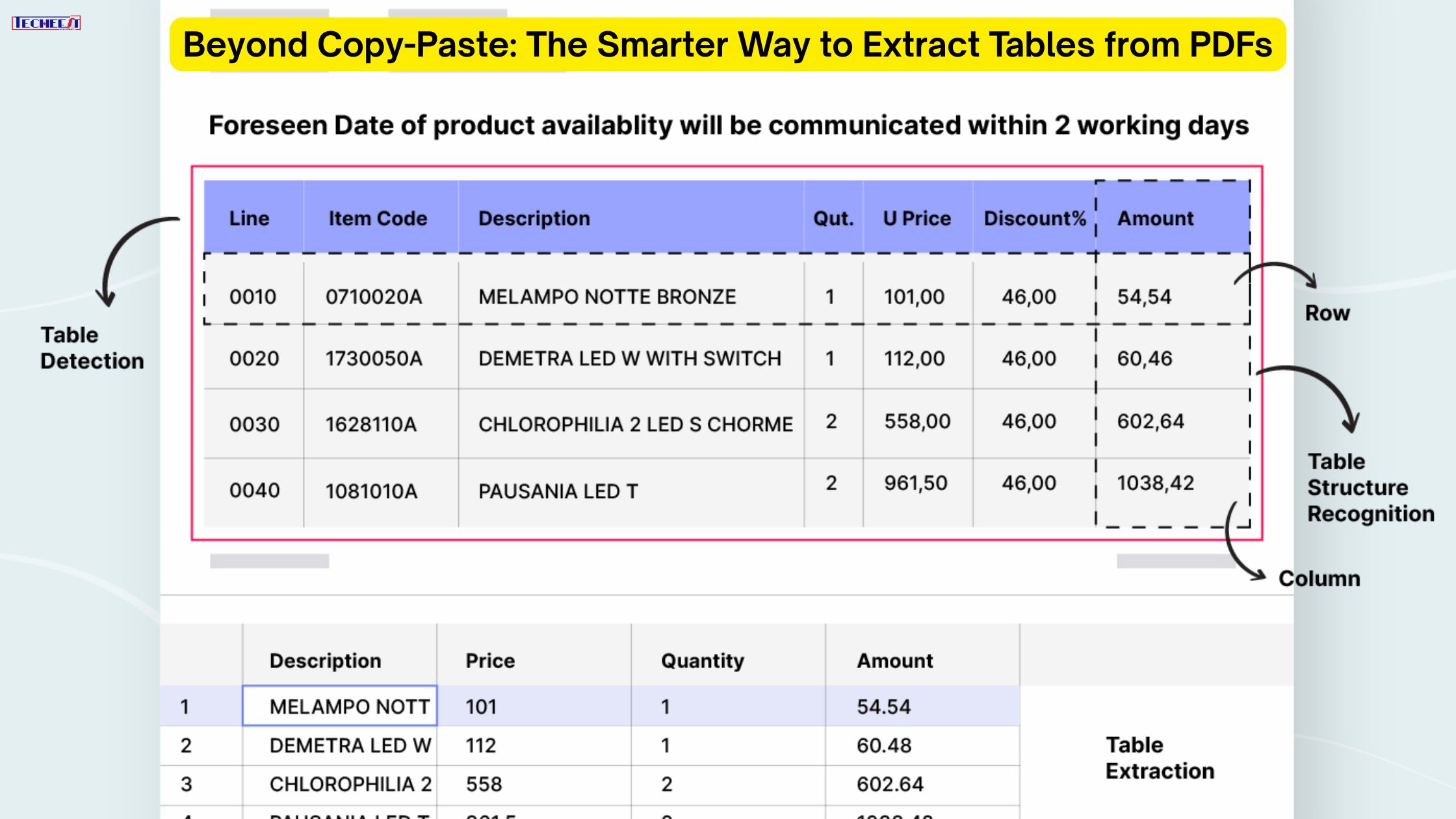
We’ve all been there: watching a superbly dependent desk within a PDF, wanting that statistics for analysis, a report, or in reality to get work finished. Your first instinct? The trusty “reproduction-paste” method. But almost right away, frustration units in. Rows scramble, columns misalign, crucial information is going missing, and what started as a short task devolves into a tedious consultation of manual reformatting and blunder-checking. This is not simply disturbing; it’s an enormous waste of time and a breeding ground for inaccuracies.
But what if there was a better manner? This article will dive into the “smarter way” to extract tables from PDFs – leveraging automated and noticeably green strategies that absolutely bypass the pitfalls of guide reproduction-pasting. We’ll explore why conventional techniques fall short, highlight the huge benefits of adopting intelligent extraction techniques, and guide you through various established techniques and effective equipment to be had nowadays. Get ready to convert your PDF records workflow and unlock the actual ability of your facts.
The Pain Points of Manual PDF Table Extraction
The “reproduction-paste” technique, while quick, speedy, becomes a nightmare whilst handling PDF tables. Here’s why it is an exercise ripe with frustration and inefficiency:
- Formatting Loss is Guaranteed: When you replica data from a PDF and paste it right into a spreadsheet like Excel or Google Sheets, you rarely get smooth, dependent information. Instead, you’re frequently left with jumbled records, textual content from a couple of cells merged into one, or columns which might be hopelessly misaligned. It’s a virtual jigsaw puzzle with 1/2 the pieces missing or incorrectly reduced.
- Data Goes Missing: It’s not unusual for individual cells or maybe complete rows to be skipped or incorrectly interpreted at some stage in the manual copy method. This method your extracted statistics is incomplete and unreliable right from the start.
- Time Consumption is Astronomical: For absolutely everyone handling massive tables spanning multiple pages, or needing to extract data from numerous PDF documents, manual reproduction-pasting is a very sluggish and tedious technique. What need to take mins can without difficulty stretch into hours, or even days.
- Error-Prone and Unreliable: Human errors are an unavoidable element in guide information entry. Whether it’s a typo, and not noted price, or a misaligned column, the likelihood of introducing inaccuracies for the duration of guide transcription or correction is particularly high, compromising the integrity of your data.
- Scalability is Non-Existent: Imagine trying to extract records from masses or even lots of PDF financial reviews, studies papers, invoices, or felony files the use of handiest copy-paste. It’s simply impossible to scale this technique efficaciously, making big-scale fact initiatives unmanageable.
These challenges spotlight why counting on guide techniques for PDF desk extraction is not simply inconvenient, but essentially unsustainable for any extreme records-pushed assignment.
Why Go Beyond Copy-Paste? The Benefits of Smart Extraction
Moving past the manual grind of reproduction-pasting is not just about keeping off frustration; it is approximately unlocking a brand-new degree of productivity and statistics ability. Here’s why adopting smart PDF desk extraction strategies is a game-changer:
- Unmatched Accuracy: Automated gear considerably lessens human blunders, making sure the records you extract is smooth, complete, and dependable. This approach fewer mistakes for your reviews and analyses, main to greater assured decision-making.
- Massive Efficiency & Time Savings: Imagine processing a 50-page economic record’s tables in minutes as opposed to hours. Smart extraction notably cuts down the time required for statistics series, releasing you and your group to awareness on better-feeling tasks like evaluation and approach, now not tedious statistics entry.
- Effortless Scalability: Need to pull facts from hundreds or maybe thousands of PDFs? Automated answers take care of batch processing effectively, making massive-scale statistics initiatives now not simply possible, but simple. What changed into once a daunting venture turns into a routine operation.
- Instant Data Usability: Smart tools do not simply extract text; they pull information directly into established formats like CSV, Excel, or JSON.6 This way, your statistics are without delay prepared for evaluation, database import, or integration into other applications without extra formatting.
- Paving the Way for Automation: Once you have a dependable manner to extract facts, you open the door to complete workflow automation. Connect your extraction method with other tools to create seamless, end-to-end facts pipelines, minimizing manual intervention.
- Focus on Insights, Not Entry: By offloading the grunt work of statistics access, you may shift your cognizance from the mundane undertaking of transcription to the crucial work of deriving insights from your information. This elevates your role and the value you convey to any venture.
Embracing smart extraction isn’t simply an upgrade; it is a fundamental shift towards extra intelligent, reliable, and efficient information management.
Understanding How Smart Extraction Works (Under the Hood)
So, how do these “smart” tools acquire what guide reproduction-paste cannot? It all boils all the way down to sophisticated underlying technology that allows them to “examine” and apprehend PDFs a long way past an easy visual display.
- Optical Character Recognition (OCR) for Scanned PDFs: Not all PDFs are created identical. If you are managing a scanned document – essentially a photograph of text – the pc doesn’t see actual characters, but rather a group of pixels. This is where Optical Character Recognition (OCR) is available. OCR technology analyzes the photo, identifies patterns that correspond to letters and numbers, and converts them into system-readable textual content. For tables in scanned PDFs, OCR is the vital first step to even make the records extractable.
- PDF Structure Analysis for Native PDFs: For PDFs created digitally (native PDFs), the manner is one of a kind and often more specific. These documents comprise embedded information approximately the textual content, fonts, and layout. Smart extraction software program leverages PDF shape analysis, which entails parsing the PDF’s internal code. It looks for visible cues like:
- Lines and Borders: Identifying actual lines or perceived boundaries that outline cells and rows.
- Spacing and Alignment: Analyzing the constant spacing among text factors to infer column and row systems.
- Font and Text Patterns: Recognizing repeating patterns in font sizes, patterns, and text go with the flow suggests tabular records.
However, challenges remain, consisting of merged cells (where one mobile spans a couple of columns or rows) or spanning rows/columns, that may confuse less complicated algorithms.
Pattern Recognition & AI/ML: The maximum advanced gear crosses a step further, using Pattern Recognition and Artificial Intelligence (AI) and Machine Learning (ML). These algorithms are educated on sizeable datasets of numerous PDF tables, letting them:
- Learn and Adapt: Identify complicated table systems even without specific lines or steady formatting.
- Contextual Understanding: Use context clues from the encircling text to deduce table limitations and relationships between information factors.
- Improve Over Time: Continuously refine their accuracy as they procedure extra files and come upon new desk layouts. This is in particular useful for coping with highly variable or “unstructured” table formats.
By combining those powerful techniques, smart extraction tools can as it should be discover, interpret, and extract tabular statistics, turning static PDF content into dynamic, usable data.
Methods for Smart PDF Table Extraction (Practical Approaches)
Now that we understand the ‘why’ and ‘how’ of clever extraction, let’s explore the sensible methods you can employ, starting from simple net tools to powerful programming libraries. Choosing the proper method relies upon your particular desires, technical comfort, and the dimensions of your mission.
Online PDF Table Extractors (Easiest, Quick Wins)
For the ones seeking out instant effects without any software installation, online gear is your first-rate wager.
- Description: These are net-based platforms wherein you truly add your PDF record, and the carrier approaches it, permitting you to download the extracted table facts, usually in formats like CSV or Excel.
- Pros: They are pretty person-friendly, requiring no technical knowledge or software installation. They’re ideal for occasional use or whilst you want a short answer for a single record.
- Cons: A primary concern is information privacy – you are uploading doubtlessly touchy documents to a 3rd-party server. They regularly come with barriers on document length, the number of pages, or the full files you can technique of their free ranges, requiring subscriptions for advanced functions. You also have less managed over the extraction manner in comparison to other strategies.
- Examples: Popular alternatives consist of Tabula (an open-source, web-based device that can also be run regionally), Smallpdf, and Adobe Acrobat’s online gear, which offer primary desk recognition functions.
Dedicated Desktop Software (More Control, Offline)
When data privacy is a situation, otherwise you require extra strong capabilities and offline talents, committed desktop software program solutions are perfect.
- Description: These are programs you install without delay onto your pc, imparting a secure, offline environment for processing your PDFs. They commonly offer a richer set of functions for desk popularity and facts manipulation.
- Pros: The primary advantages are offline abilities (no net needed after set up) and appreciable extra manage over the extraction method. They are regularly better geared up to address complicated tables, offer batch processing for a couple of files, and provide superior editing functions before export.
- Cons: The maximum substantial drawback is often the value, as most professional laptop software comes with a license price. Additionally, it requires software program setup and renovation.
- Examples: Industry requirements encompass Adobe Acrobat Pro (which has robust desk popularity and export capabilities), ABBYY FineReader (renowned for its advanced OCR and table extraction), and Nitro Pro.
Programming Libraries (For Developers & Automation Enthusiasts)
For maximum flexibility, customization, and large-scale automation, programming libraries are the go-to solution for developers and tech-savvy customers.
- Description: These are code-primarily based tools that assist you to write scripts to programmatically extract tables from PDFs. This technique offers the very best stage of customization and integration.
- Pros: They are pretty customizable, allowing you to tailor the extraction logic to even the most specific or hard desk structures. They are best for huge-scale automation, allowing you to procedure thousands of documents without guide intervention. Furthermore, many are open-source and unfastened, warding off supplier lock-in.
- Cons: The primary barrier is the requirement for coding knowledge (e.g., Python or R), which means a steeper studying curve for beginners.
- Examples:
- Python: Excellent libraries consist of Camelot (great for specific table extraction), Tabula-py (a Python wrapper for the Tabula Java library, precise for statistics in non-popular tables), and PyPDF2 (beneficial for primary text extraction that may then be parsed for tables).
- R: The tabulizer package is a famous desire for R customers.
- When to apply this technique: Opt for programming libraries when you want to combine PDF extraction into a larger automatic gadget, process heaps of documents regularly, or whilst you come upon particular, inconsistent, or exceptionally complicated desk structures that off-the-shelf software struggles with.
Best Practices for Successful Table Extraction
Even with the neatest gear, a little foresight and interest to detail can appreciably enhance your PDF table extraction fulfillment rate. Adopt those excellent practices to make certain accurate and green statistics retrieval:
- Choose the Right Tool for the Job: Don’t use a hammer for each nail. Evaluate your wishes: Is it an occasional, easy table, or common, complex extractions? Do you have programming abilities? Matching the tool (online, desktop, or library) on your particular use case and technical comfort is paramount for top-of-the-line outcomes.
- Pre-method Your PDFs (If Necessary): The pleasant of you enter PDFs directly affects output accuracy, particularly for scanned documents. Ensure your PDFs aren’t skewed, turned around, or of excessively low resolution, especially while relying on OCR. A quick cleanup could make a large difference.
- Always Review and Verify: No extraction device is 100% foolproof. Always perform a short sanity test of the extracted records against the original PDF. Look for obvious errors, lacking rows, or misaligned columns. This vital step catches inconsistencies earlier than they turn out to be larger troubles.
- Understand and Handle Complexities: PDFs can be elaborate. Be privy to commonplace demanding situations like merged cells (in which one cell spans more than one column), invisible desk strains, or tables that span across more than one page. Some advanced tools are mainly designed to handle those complexities better than others.
- Consider Data Privacy and Security: If your PDFs comprise sensitive or confidential facts, be extraordinarily careful with on line equipment. Always overview their records dealing with policies and phrases of carrier. For rather touchy facts, offline computing device software or local programming libraries offer advanced security.
By following these recommendations, you’ll maximize the effectiveness of your smart extraction efforts, turning PDF tables into usable facts with self-belief.
Conclusion
The days of wrestling with PDF tables and the use of guide reproduction-paste are, luckily, behind us. As we have visible, that tedious method inevitably ends in frustrating formatting troubles, lacking statistics, and substantial time wastage. By embracing smarter extraction methods – whether or not via intuitive online tools, robust laptop software program, or powerful programming libraries – you unencumber colossal benefits: unheard of accuracy, dramatic time savings, easy scalability, and immediately usable statistics. Efficient PDF desk extraction is not a luxury for experts; it is an essential necessity for present-day records workflows. It transforms an infamous bottleneck right into a streamlined procedure, allowing you to shift awareness from mundane information access to impactful evaluation. So, forestall copying, and start extracting well – your productivity and your facts will thank you for it.